
Tek Nicel Değişkenli Veri Dağılımları ile Çalışma ve Veriye Dayalı Karar Verme
Günlük yaşantımızda, çevremizde veya medyada karşılaştığımız birçok bilgi aslında veriye dayalıdır. Bir şirketin aylık satış rakamlarından bir ülkenin ortalama sıcaklık değerlerine, sporcuların performanslarından bir ürünün kullanım sürelerine kadar pek çok durum nicel verilerle ifade edilir. Bu verileri anlamak, yorumlamak ve bunlara dayanarak doğru kararlar almak, istatistik biliminin temel amaçlarından biridir. Özellikle tek bir nicel değişkenin dağılımını incelemek, istatistiksel araştırmanın ilk ve en önemli adımlarından biridir.
Nicel Veri ve İstatistiksel Bağlam
İstatistik, çevremizdeki dünyayı anlamak için verileri kullanır. Ancak her veri aynı değildir. İstatistiksel araştırmalarda karşılaştığımız verileri genellikle iki ana kategoriye ayırırız: nitel ve nicel veriler.
Nicel Veri: Bir grubun özelliklerini sayma veya ölçme yoluyla elde edilen, sayısal olarak ifade edilebilen verilerdir. Örneğin, öğrencilerin boyları, bir şehrin yıllık yağış miktarı, bir ürünün ağırlığı nicel verilerdir.
Nitel Veri: Kategorik özelliklere dayalı, sayısal olmayan verilerdir. Örneğin, saç rengi, cinsiyet, favori spor dalı nitel verilerdir.
Bu konuda, özellikle tek nicel değişkenli verileri analiz etmeye odaklanacağız. Yani, bir durumdaki sadece bir sayısal özelliği ele alarak onun dağılımını inceleyeceğiz. İstatistiksel araştırmanın temeli, veriye dayalı bilgi üretme ihtiyacı duyduğumuz gerçek yaşam durumlarıdır. Bu durumlara bağlam adını veririz. İyi bir istatistiksel araştırma, net bir bağlamla başlar.
Örneğin, “küresel ısınma nedeniyle Dünya’nın ortalama yüzey sıcaklığının artması” bir gerçek yaşam durumudur. Bu durumdan yola çıkarak, “Dünya’nın ortalama yüzey sıcaklığındaki değişim” tek nicel bir değişkendir ve bu, istatistiksel araştırmamızın bağlamını oluşturur.
İstatistiksel Araştırma Sorusu Oluşturma
Bağlam belirlendikten sonra, araştırmamıza yön verecek istatistiksel araştırma sorularını oluştururuz. Bu sorular, veri toplama ve analiz sürecimizin yol haritasıdır. İyi bir araştırma sorusu, hem açık hem de ölçülebilir olmalıdır.
İstatistiksel araştırma soruları genellikle iki ana türde olabilir:
- Betimleyen Araştırma Soruları: Bir grubun veya dağılımın belirli bir özelliğini tanımlamaya odaklanır. Örneğin, “Lise öğrencilerinin haftalık fiziksel etkinlik süreleri nasıl bir eğilim göstermektedir?”
- Karşılaştıran Araştırma Soruları: İki veya daha fazla grup arasındaki bir özelliği karşılaştırmaya odaklanır. Örneğin, “Erkek ve kız öğrencilerin haftalık fiziksel etkinlik süreleri arasında nasıl bir farklılık bulunmaktadır?”
Bir istatistiksel araştırma sorusu oluştururken dikkat etmemiz gereken bazı önemli ölçütler şunlardır:
| Ölçüt | Açıklama |
|---|---|
| Amacı Net Olmalıdır | Soru, betimleyici mi yoksa karşılaştırıcı mı olduğunu açıkça belirtmelidir. |
| Araştırmaya Değer Olmalıdır | Elde edilecek bilgilerin anlamlı ve faydalı olması gerekir. |
| İlgilenilen Grup (Evren) Açık Olmalıdır | Araştırmanın kimler hakkında bilgi topladığını net bir şekilde belirtmelidir. (Ör: “A lisesindeki 9. sınıf öğrencileri”) |
| Değişken Açıkça Görülmelidir | Hangi özelliğin ölçüldüğü veya sayıldığı anlaşılır olmalıdır. (Ör: “haftalık fiziksel etkinlik süresi”) |
| Veri Toplanarak Cevaplanabilmelidir | Soruyu yanıtlamak için gerçekte veri toplanabilir olmalıdır (birincil veya ikincil verilerle). |
| Değişebilirliği Yansıtmalıdır | Verilerde bir çeşitlilik, farklılık beklenmelidir. Tek bir cevabı olan sorular istatistiksel değildir. |
| Odaklanılan Grup Araştırma Yapılmasına İmkan Vermelidir | Soru, bireysel değerlerden ziyade bir grubun genel eğilimlerine odaklanmalıdır. |
| Nicel Veri Toplamaya Uygun Olmalıdır | Soru, sayısal olarak ölçülebilen veya sayılabilen verileri gerektirmelidir. |
Bir ilkokulun 3. sınıf öğrencilerinin boylarını incelemek isteyen bir araştırmacı, “Öğrencilerin boyları ne kadardır?” ve “Erkek öğrencilerin boyu, kız öğrencilerin boyundan daha mı uzundur?” sorularını sormuştur.Değerlendirme:
- “Öğrencilerin boyları ne kadardır?” sorusu, hangi okulun veya hangi öğrencilerin kastedildiğini tam olarak belirtmediği için “İlgilenilen grup açık olmalıdır” ölçütünü eksik bırakmaktadır. Yeniden düzenlenmiş hali: “A ilkokulunda öğrenim gören 3. sınıf öğrencilerinin santimetre cinsinden boyları nasıl bir eğilim göstermektedir?”
- “Erkek öğrencilerin boyu, kız öğrencilerin boyundan daha mı uzundur?” sorusu, bir önyargı içerdiğinden “Amacı net olmalıdır” ölçütünde geliştirilebilir. Ayrıca ölçüm birimi ve evren netleştirilmelidir. Yeniden düzenlenmiş hali: “A ilkokulunda öğrenim gören 3. sınıf öğrencilerinin boyları, cinsiyete göre santimetre cinsinden nasıl farklılık göstermektedir?”
Veri Toplama Planı Yapma, Verileri Toplama ve Analize Hazır Hale Getirme
İstatistiksel araştırma sürecinin ikinci aşaması, oluşturulan araştırma sorularına cevap bulmak için kapsamlı bir veri toplama planı hazırlamak ve verileri analiz için hazır hale getirmektir. İyi bir plan, doğru ve güvenilir sonuçlara ulaşmanın anahtarıdır.
| Adım | Açıklama |
|---|---|
| 1. Veri Toplama Araçlarını Belirleme | Anketler, görüşme formları, ölçüm cihazları gibi veriyi elde edeceğimiz araçları seçmek veya tasarlamak. Veriler birincil (kendimiz topladığımız) veya ikincil (mevcut) olabilir. |
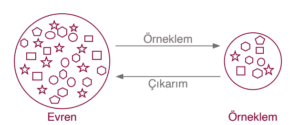
| 2. Evren ve Örneklemi Belirleme | Evren, araştırmanın sonuçlarının genelleneceği tüm topluluktur. Örneklem ise evrenden seçilen, evreni temsil eden daha küçük bir kümedir. |
| 3. Rastgeleliği Sağlama | Örneklemin evreni en iyi şekilde temsil etmesi için, evrendeki her elemanın örnekleme seçilme olasılığının eşit olması (rastgelelik) sağlanmalıdır. Basit rastgele örnekleme yöntemleri (kura çekimi gibi) kullanılabilir. |
| 4. Değişkenleri Belirleme | Araştırılacak nicel değişkenin yanı sıra, bu değişkeni etkileyebilecek olası diğer faktörleri de belirlemek önemlidir. |
| 5. Toplama Yeri, Zamanı, Şekli ve Kişileri Belirleme | Verilerin nerede, hangi zaman aralığında, nasıl (yüz yüze, çevrim içi vb.) ve kimler tarafından toplanacağını planlamak. |
| 6. Verilerin Kaydedilmesi | Toplanan verilerin elektronik tablolama programları (Excel) veya istatistik yazılımlarına (R, Python, SPSS gibi) düzenli ve hatasız bir şekilde girilmesi. |
| 7. Gizlilik, Dürüstlük ve Nesnellik | Kişisel verilerin korunması, etik kurallara uyum ve verilerin tarafsız bir şekilde, beklentilerden etkilenmeden kaydedilmesi esastır. Gerekirse resmi izinler alınmalı, reşit olmayan katılımcılar için veli onayı sağlanmalıdır. |
Nicel Veriye Dayalı İstatistiksel Araştırmalarda Veri Analizi Yapma ve Sonuçları Yorumlama
Veriler toplandıktan ve analize hazır hale getirildikten sonra sıra, bu verileri anlamlı bilgilere dönüştürmeye gelir. Veri analizi, istatistiksel araştırma sorularımıza cevap bulmak için uygun görselleştirme ve özetleme araçlarının kullanılmasını içerir.
Veri Görselleştirme Araçları
Veri dağılımını daha iyi anlamak için çeşitli grafikler kullanırız:
- Nokta Grafiği (Dot Plot): Her bir veri noktasının sayı doğrusu üzerindeki konumunu gösterir. Verilerin nerede yoğunlaştığını, yayılımını ve aykırı değerleri hızlıca görmemizi sağlar.

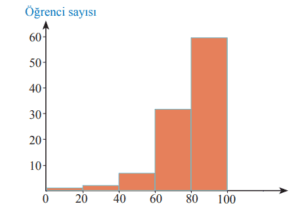
- Histogram: Nicel verilerin belirli aralıklardaki (sınıf aralıkları) sıklığını (frekansını) sütunlarla gösteren bir grafiktir. Verilerin genel şeklini, merkezini, yayılımını ve modunu (en sık görülen aralık) anlamak için idealdir.

- Kutu Grafiği (Box Plot): Bir dağılımın beş sayılı özetini (minimum, alt çeyrek (Ç1), ortanca (Ç2), üst çeyrek (Ç3), maksimum) görselleştiren güçlü bir araçtır. Özellikle dağılımları karşılaştırmak ve aykırı değerleri (outliers) tespit etmek için kullanılır.

Beş Sayılı Özet:
- Minimum (Alt Uç Değer): Veri setindeki en küçük değer.
- Alt Çeyrek (Q1 veya %25’lik Dilim): Verilerin ilk %25’ini kapsayan değer. Yani verilerin %25’i bu değerin altındadır.
- Ortanca (Medyan, Q2 veya %50’lik Dilim): Sıralanmış veri setinin tam ortasındaki değer. Verilerin %50’si bu değerin altındadır.
- Üst Çeyrek (Q3 veya %75’lik Dilim): Verilerin ilk %75’ini kapsayan değer. Yani verilerin %75’i bu değerin altındadır.
- Maksimum (Üst Uç Değer): Veri setindeki en büyük değer.
Çeyrekler Açıklığı (Interquartile Range – IQR): Q3 – Q1 olarak hesaplanır ve verilerin ortadaki %50’sinin yayılımını gösterir. Aykırı değerlerden etkilenmediği için yayılım hakkında daha güvenilir bir bilgi sunar.

Veri Özetleme Araçları (Merkez ve Yayılım Ölçüleri)
Görselleştirmelerin yanı sıra, nicel verileri tek bir sayısal değerle özetleyen ölçüler de kullanırız:
Merkezi Eğilim Ölçüleri (Central Tendency)
Verilerin etrafında toplandığı, yani merkeze yığıldığı değerleri gösterir.
- Aritmetik Ortalama (Mean): Tüm veri değerlerinin toplamının veri sayısına bölünmesiyle bulunur. Aykırı değerlerden (çok büyük veya çok küçük) oldukça etkilenir.
\[ \text{Aritmetik Ortalama} = \frac{\sum x_i}{n} \] - Ortanca (Median): Veriler küçükten büyüğe sıralandığında tam ortada yer alan değerdir. Eğer veri sayısı tek ise ortadaki değer, çift ise ortadaki iki değerin ortalamasıdır. Aykırı değerlerden aritmetik ortalama kadar etkilenmez.
Yayılım Ölçüleri (Measures of Spread/Variability)
Verilerin ne kadar yayıldığını, yani birbirinden ne kadar farklılaştığını gösterir. Değişebilirlik, doğal ortamdan, ölçümden, müdahaleden veya örneklemden kaynaklanabilir.
- Açıklık (Range): Veri setindeki en büyük değer ile en küçük değer arasındaki farktır. Veri yayılımı hakkında hızlı bir bilgi verse de, yalnızca uç değerlere baktığı için aykırı değerlerden çok etkilenir.
\[ \text{Açıklık} = \text{Maksimum Değer} – \text{Minimum Değer} \] - Ortalama Mutlak Sapma (Mean Absolute Deviation – MAD): Her bir veri değerinin aritmetik ortalamadan ne kadar uzaklaştığının mutlak değerlerinin ortalamasıdır.
\[ \text{MAD} = \frac{\sum |x_i – \text{Aritmetik Ortalama}|}{n} \] - Standart Sapma (Standard Deviation – SD): Verilerin aritmetik ortalamadan ne kadar yayıldığını gösteren, daha hassas ve yaygın kullanılan bir ölçüdür. Karesel farkların ortalamasının kareköküdür. Aykırı değerlerden etkilenir ancak MAD’den daha güvenilir bir yayılım aralığı sunar.
\[ \text{SD} = \sqrt{\frac{\sum (x_i – \text{Aritmetik Ortalama})^2}{n-1}} \] - Çeyrekler Açıklığı (Interquartile Range – IQR): Q3 – Q1. Verilerin ortadaki %50’sinin ne kadar yayıldığını gösterir ve aykırı değerlerden diğer yayılım ölçülerine göre daha az etkilenir.
2023 Dünya Atletizm Şampiyonası erkekler 100 metre koşusu verileri incelenirken:
- En yüksek ve en düşük performans arasındaki fark (Açıklık): En hızlı atlet 9.86 saniye, en yavaş atlet 11.58 saniye koşmuşsa, açıklık \(11.58 – 9.86 = 1.72\) saniyedir.
- Koşu derecelerinin nasıl bir eğilim gösterdiği (Merkezi Eğilim): Aritmetik ortalama 10.299 saniye, ortanca ise 10.2 saniyedir. Aykırı değerler aritmetik ortalamayı etkilediğinden, ortancanın dağılımın merkezi için daha iyi bir gösterge olabileceği sonucuna varılır. Yani, koşu dereceleri yaklaşık 10.2 saniye etrafında toplanmıştır.
- Merkeze yığılan performans derecelerinin aralıkları (Kutu Grafiği ile): Alt çeyrek (Q1) 10.11 saniye, üst çeyrek (Q3) 10.32 saniye ise, atletlerin %50’sinin dereceleri bu aralıktadır.
- 0.2 saniyelik aralıklarla yoğunlaşma (Histogram ile): Örneğin, 10 saniye ile 10.2 saniye arasında 23 atletin derecesi bulunmaktadır. Bu, verilerin belirli aralıklardaki sıklığını netleştirir.
- Ortalama değere göre yayılım (MAD ve SD): Ortalama mutlak sapma ±0.24 saniye, standart sapma ±0.349 saniyedir. Standart sapma aralığı, verilerin ortalamadan daha geniş bir yayılımını kapsar.
Veri analizi yapıldıktan sonra, elde edilen sonuçlar araştırma soruları doğrultusunda dikkatlice yorumlanmalıdır. Görselleştirme ve özetleme araçları, verilerin bize anlattığı hikayeyi ortaya çıkarır. Bu yorumlar, gerçek yaşam durumlarına ilişkin kararlar almamızı veya mevcut durum hakkında öngörülerde bulunmamızı sağlar.
Tek nicel değişkenli veri dağılımlarını anlamak, istatistiksel düşünmenin temelidir. Bu becerileri kazanarak, çevremizdeki sayısal bilgileri daha bilinçli bir şekilde değerlendirebilir ve veriye dayalı kararlar alabiliriz.